試験開発プロセス
標準化試験は、教育や産業など多様な分野で活用されており、教育機関・企業・人事担当者・政策立案者が、学習者や求職者、従業員、さらには教育プログラムや組織全体の評価を行う際に重要な役割を果たしています。 こうした試験には、公平で正確なデータ指標を提供し、最高水準の専門性・技術・倫理基準を満たすことが求められます。
OpenEDG Python Instituteの認定試験は、特定分野の知識・スキル・能力・適性を正確に測定するために設計されており、公正性・妥当性・信頼性・安全性のすべてを兼ね備えた評価ツールとなるよう開発されています。
OpenEDGでは、試験および認定資格の開発プロセスを厳格かつ包括的に管理しており、分野専門家との協働を重視しています。 各工程では、専門家による検討とレビューを重ね、実践的スキルの評価に焦点を当てた設計・開発・検証を行います。 質的開発フレームワークや科目中心設計手法、心理測定モデル(サイコメトリック・モデル)を活用し、細部まで精密なアプローチを採用しています。

試験開発は、相互に関連するいくつかの段階で構成されています。
- 市場調査と分析 – これは開発プロセス全体の基盤となります。業界や市場の動向を徹底的に調査し、職業分析(JTA)、トレーニングニーズ分析(TNA)、スキルギャップ分析(SGA)などを通じて、企業が求める業務内容やスキルセットを明確化します。また、教育現場で実際に教えられている内容も調査し、教育と産業界のギャップを見極めています。こうした質的・量的な調査研究をもとに、認定取得者がITやプログラミング分野で活躍できる力を身につけられるよう設計しています。
- シラバス開発 – この段階では試験の目的やターゲット層(職務分析・専門基準の評価)を定め、試験文書の作成や試験構成や内容の初期設定を行います。分野ごとの専門家(SME)と心理測定の専門家が連携し、「プロフェッショナルによる、プロフェッショナルのための認定」を実現しています。
- 試験設計と開発 – これは最も重要な段階であり、実際の試験内容が作成されます。ここでは、認定プログラムマネージャー、関係者、心理測定専門家、SME、テスト作成者、開発者が協力し、試験の構成や出題形式、配信方法、採点基準
問題文の作成などを進めます。主に以下の6つのフェーズで構成されています。
- 構造開発:セクション数、出題項目数、試験時間、出題形式、採点モデル、図表や資料の有無、出題順序、レポートグループなど、テスト仕様(ブループリント)を定義する。
- 問題作成:問題文の作成、スクリーニング、技術レビュー – 正解・選択肢の定義、図表や資料の要件定義、技術的な検証を行う。
- 資料作成:試験項目を補足するメディアやシミュレーション、図表などを作成・実装する。
- 校正:言語編集、技術再校正、誤字脱字の確認を行う。
- 問題選定と実装:問題プールから出題問題を選定し、内部レビュー用のローカル試験テストシステムでのソースファイルの作成と実装を行う。
- 内部レビューとデプロイ – 模擬環境で試験を組み上げ、SMEによるテスト・修正を実施し、リリース前にエラーを徹底排除する。(パイロットテスト(SMT))
- 小規模市場試験(SMT) – これはベータテスターやフォーカスグループを対象に実施されるパイロットテスト段階です。受験者には誤解を招く可能性のある項目、表現が不適切な項目、正解が複数ある問題などを指摘してもらい、内容の精度を高めます。
- 最終レビューと評価 – この段階では、各試験項目と試験全体のパフォーマンスについて分析を行います。具体的には、問題の難易度に関する潜在的な課題の診断、試験問題用の相関性の診断、採点基準の確認、想定される合格率や試験時間の推定などが含まれます。このプロセスを経て、最終的に修正・更新された公開用の試験バージョン(運用用問題プールおよび最終仕様の組み合わせ)の準備が整います。
- 試験公開 – 設計・テスト・評価・更新を経て、リリースの準備が整った試験は、シリーズコードを付与し、OpenEDG テストサービス(TestNow™)や世界中の認定試験センターのグローバルネットワークを通じて利用可能になります。この段階では、プロセスを効果的、タイムリー、かつ成功させるために、プロダクトマネージャーと試験配信担当者が連携し、円滑なリリースを実現します。
- 試験のメンテナンス – 試験の設計と開発は継続的なプロセスであるため、試験が公開され、受験者が受験を開始すると、試験メンテナンス段階に入ります。この段階では、受験者のデータやフィードバックを分析し、必要に応じて内容の改善やアップデートを実施します。これは、試験内容が再検討され、試験設計プロセス全体が最初からやり直されることを意味します。公開から2年ごと、または一定数の受験者到達時(いずれか早い方)に、試験内容の再評価と更新を行い、常に最新かつ信頼性の高い認定を維持しています。
評価プロセス
OpenEDG Python Institute は、試験の妥当性を確保するため、教育・心理評価の実践に関する指針である「教育・心理テスト基準」(AERA、APA、NCME)ならびに「欧州テストユーザー基準」および「欧州テストレビューモデル」(EFPA、EAWOP)に準拠した検証を実施しています。
評価プロセスは、試験プログラムの設計、開発、実施の各段階で収集されたあらゆる証拠を徹底的に精査することから始まります。この過程では、テスト発行者、専門分野の有識者、心理測定の専門家が協力し、反復的に検討を重ねます。また実際の受験者によるフィールドテストから得られたデータも包括的に分析します。その結果、評価および試験運用の妥当性は、業界のベストプラクティス、倫理基準、主要な研究文献と整合し保証されます。このような発行者、専門家、心理測定専門家による反復的な協力プロセス、および各種基準との比較検証が、最終的な評価結果および推奨事項の基礎となります。
項目応答理論(IRT):一元性の検証
Python Institute の試験では、従来の固定形式の試験とは異なり「ランダム-ランダム」サンプリング手法を採用しています。これにより、問題バンクから各設問ごとに複数のバージョンの中からランダムに1つが出題されるため、固定された試験形式は存在しません。この仕組みにより、不正行為や問題の流出を防止しています。
項目レベルの分析は、項目応答理論(IRT)を基本的な枠組みとして実施しています。従来の古典的テスト理論(CTT)と比較して、IRT は、新規および既存の評価尺度の心理測定評価において、標準的な手法として推奨されています。IRTの基本的な考え方は、受験者が各設問にどのように回答するかは、「受験者の能力(または複数の能力)」と「設問の特性」の2要素によって決まる、というものです。
Python Instituteの試験の開発と妥当性検証では、試験問題への回答の相関が、単一の潜在的特性(すなわちPythonの習熟度/能力)が前提の一元性IRTモデルを採用しています。Pythonの習熟度のような特性/能力は、実際には多様なスキルや知識が複雑に組み合って構成されていますが、一元性の主張は、これらの構成要素が連携して一貫した全体像を形成しています。なお、試験は4~6つのトピックセクションを中心に構成されていますが、これは異なる特性を測定するのではなく、適切な領域サンプリングを提供するために行われています。
一元的な試験においては、受験者ごとにトピックの得意・不得意はあるものの、それらの体系的な関係性は、単一の潜在特性(Pythonの習熟度)が各設問への回答に与える影響によって説明されるべきものです。業界標準の文献に従い、一元性の評価(および確認)は、確認的因子分析(CFA)モデルと適合度指標(RMSEA、CFI、TLI)のレビューによって行われています。
項目応答理論(IRT):モデル概要
IRT モデルは、受験者が設問に正答する確率と、その能力レベルとの関係をモデル化するために、数式で表現します。IRTモデルの基本単位は「項目特性曲線(ICC)」であり、これは受験者の潜在能力のレベルに基づいて正答する確率を推定します。曲線形状と位置は、モデルパラメータによって推定される設問の特性によって決定されます。IRT モデルにはさまざまな形式がありますが、Python Instituteの試験評価で用いているモデルでは、正答確率は受験者の能力 (θ)、設問の難易度(b)、および認識力(a)の関数であると仮定しています。
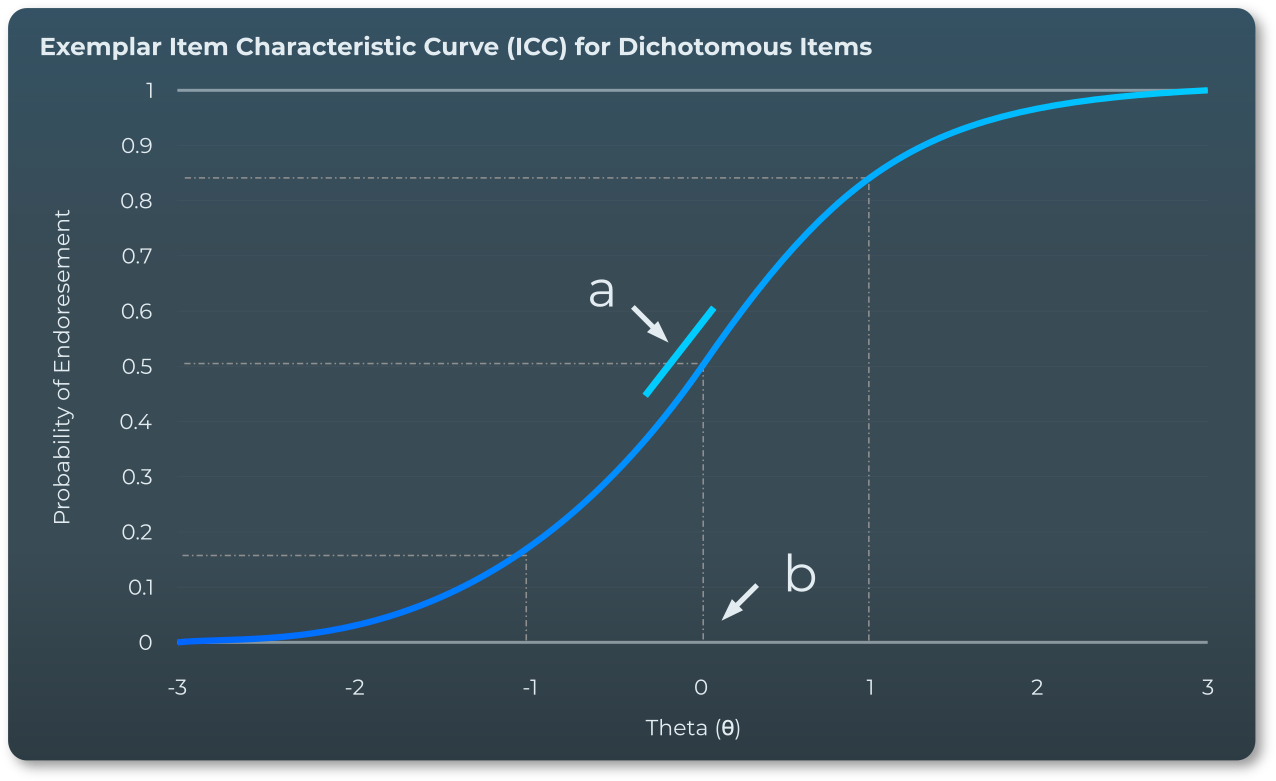
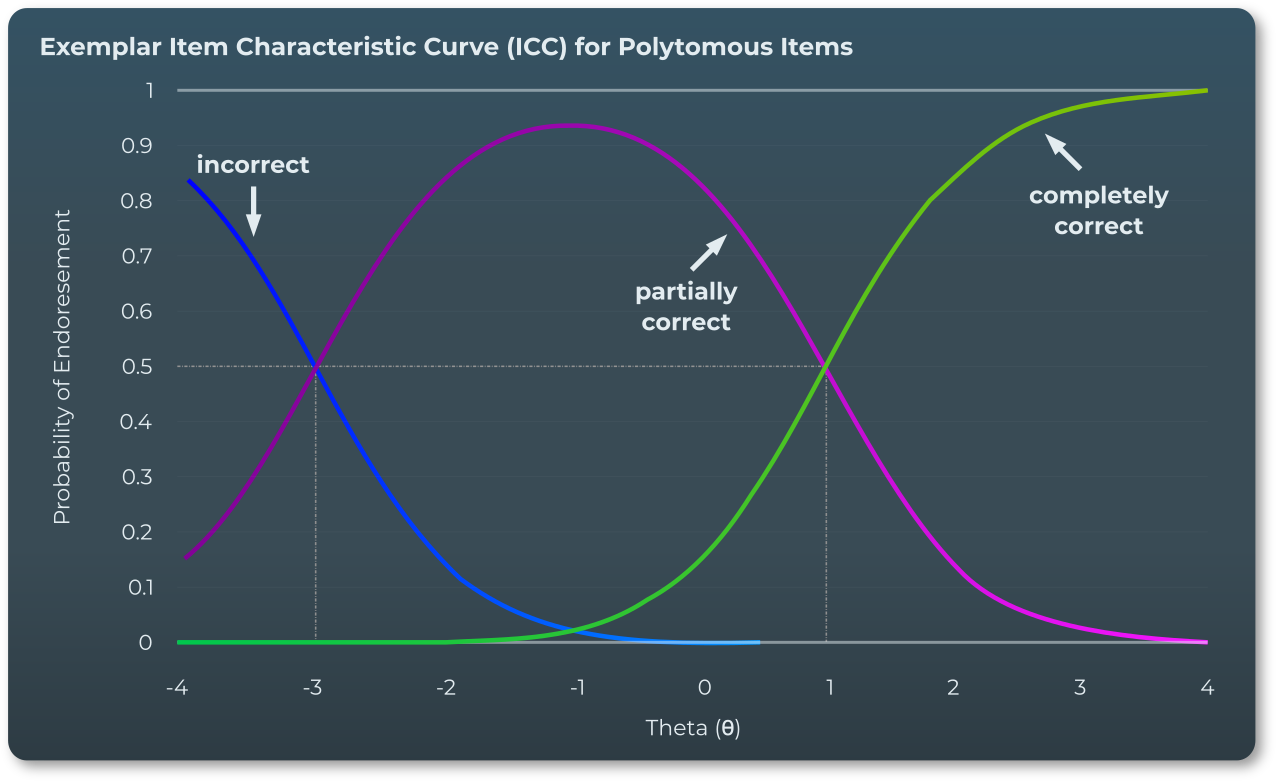
一般化部分点モデル
試験の評価は一般化部分点モデル(GPCM)と呼ばれる特定の形式の IRT モデルを使用しています。これは、二値型問題(完全正答か誤答か)と多段階項目(部分的な正答に対して部分点が得られる)の両方を評価しています。
- 部分点閾値の難易度パラメータ(b1)- 部分点が与えられる基準となる難易度を占める
- 満点閾値の難易度パラメータ(b2)- 完全正答となる基準の難易度を示す
- 識別力パラメータ(a) – 問題が受験者の能力をどの程度明確に区別できるかを示す
- 個人能力パラメータ(θ) – 標準化された受験者の能力レベルを示す
項目情報関数(IIF)
項目情報関数(IIF または I(θ))は、IRT(項目応答理論)において、各設問が受験者の能力レベル(θ)ごとにどれだけ正確な情報を提供するかを示す指標です。IIFは、ある項目が特定の能力レベルに対してどれほど高い精度で能力を測定できるか数値化しており、その値が高いほど、その能力レベルにおいてその項目が非常に有用であることを意味します。IIFのグラフは、横軸に能力値(θ)、縦軸に情報量をとった曲線として描かれます。このグラフで曲線の最も高い部分は、その項目が最も多くの情報を提供できる能力レベルを示しています。つまり、そのピーク位置は、その項目がどのような受験者にとって特に役立つか、視覚的に示しています。
また、IIF曲線の「鋭さ」も重要な意味を持ちます。曲線が急で狭く鋭いピークを持っている場合、その項目は特定の狭い能力範囲で非常に高い情報量を持つことを意味します。例えば、難易度や識別力が高い問題は、このような鋭いピークを持つことが多いです。一方、曲線がなだらかで広がっている場合は、幅広い能力範囲にわたって比較的少ない情報を分散して提供していることを示します。
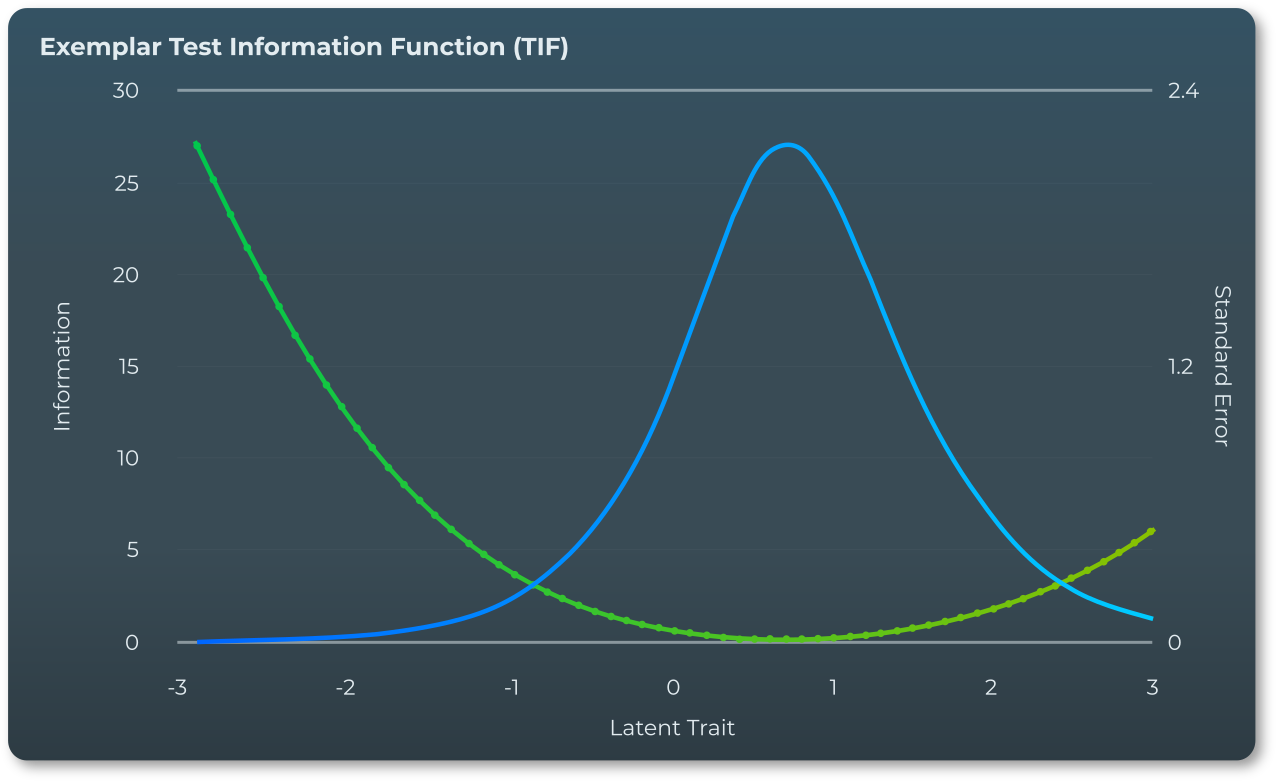
一方で「テスト情報関数(TIF)」は、試験全体がどの能力レベルで最も有効に機能するかを示します。IIFが個々の設問の精度を示すのに対し、TIFは試験全体の精度を能力レベルごとに表します。
TIFの高さは標準誤差(Standard Error of θ)の逆数として表現され、値が高いほどその能力レベルでの推定誤差が小さく、より正確な評価が可能です。実際には、TIF曲線がθ<0(平均未満)でピークを持つ場合、その試験は主に低い能力層の評価に優れていることを意味します。逆にθ>0(平均超)でピークを持つ場合は、高い能力層の評価に適していることを示します。
Python Instituteでは、TIFプロットを必ず確認し、試験が意図した能力範囲に対して十分な評価制精度を持っているかどうかを検証しています。これにより、受験者の能力レベルに応じて、試験が最適な精度で評価できることを保証しています。
ISO 9001:試験開発における品質保証
OpenEDG Python Instituteでは、最高水準の品質・一貫性・公正性を維持するため、すべての試験開発プロセスにISO 9001を導入しています。
この国際規格に基づき、手順は厳格に管理・継続的に改善され、第三者による審査・レビューも行われています。 ISO 9001のもとで、業務分析やシラバス作成から問題作成・検証・運用・改訂・維持管理に至るすべての工程が記録された手順と品質チェックポイントに従い、改訂ごとに厳格な変更管理・関係者による確認・監査記録による手順の履歴が管理されています。
この品質管理フレームワークにより、Python Instituteの認定試験はどの段階でも信頼性の高い手法で作成・提供され、受験者や教育機関、企業がその一貫性・公正性・信頼性に自信をもって活用できるものになっています。